
| Index A I | NN構成・方式 |
|
ニューラルNW 一つのノード 1ノードでの学習 3入力勾配降下法 レイヤー 多層化 誤差逆伝播法 結合の仕方など 3層構造 TowLayerNet ハイパーパラメータ 各層の計算 最適化 計算グラフ NN機能・要件 構成・方式など タスク 導入 Sample 用語 |
ニューラルネットワーク ・多層パーセプトロンのノード(ニューロン)を増やしたもの。 ・ニューロン(ノード) パーセプトロンと同じようなつながり方をする。一つのノード (ニューロン) 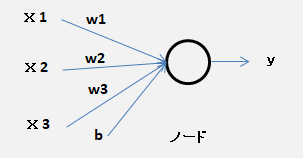 ・入力 \(x_{1},x_{2},x_{3}\) 、重み \(w_{1},w_{2},w_{3}\)(負もあり) 、バイアス \(b\)(負もあり)、閾値は常に 0 \(w_{1}\times x_{1} + w_{2}\times x_{2} + w_{3}\times x_{3} + b \lt 0\) ・・・ 0 \(w_{1}\times x_{1} + w_{2}\times x_{2} + w_{3}\times x_{3} + b \geqq 0\) ・・・ 1・ノードの 出力(\(o\)) = 入力(\(x\)) \(\times\) 重み(\(w\)) \(+\) バイアス(\(b\)) \(y = w_{1}\times x_{1} + w_{2}\times x_{2} + w_{3}\times x_{3} + b\)1ノードでの学習 ・各 \(x_{1},x_{2},x_{3}\) に対し望みの出力 \(y\) が得られるような4つの値 \(w_{1},w_{2},w_{3}, b\) を探す。 ・ノードでの学習を 最適化問題 として扱う場合、もっとも低い点を見つけるに相当する。 勾配 が降下して行く先で平坦になった時の \(y\) の値が 0 の地点 その時の重みが最適な値 ( 勾配降下法 )・入力は3要素のベクトル とみなせて、その勾配も3要素のベクトルとなる。  ・活性化関数 に シグモイド関数 を使用した場合のニューラルネットワーク(1ノード) \(y = sigmoid(w_{1}\times x_{1} + w_{2}\times x_{2} + w_{3}\times x_{3} + b)\)・関数 sigmoidの定義 重みパラメータとバイアスの学習時、x:(\(x_{1}, x_{2}, x_{3}\)) を与えると \(y\) を返す。・ニューラルネットワークでは、活性化関数に線形関数を用いてはならない。 多層の利点を生かせない。 線形関数:出力が入力の整数倍になるような関数・損失関数 の定義 損失関数 \(L\) は 出力 \(y\) と 学習したい正解値 \(y_{0}\) の差 \(L = (y - y_{0})^2\) (正負を無視、微分しやすくするため二乗) 実際の学習では \(y_{0}\) は訓練データ数だけ存在し、損失関数はそれらすべての平均 \(L_{MSE} = \sum_{}^{}(y - y_{0})^2 / N\) ( 平均二乗誤差 )・\(y\) は \(w_{1}, w_{2}, w_{3}\) と \(b\) の関数で、(\(x_{1}, x_{2}, x_{3}\)) と \(y_{0}\) は訓練データで確定 \(L_{MSE}\) 全体も \(w_{1}, w_{2}, w_{3}\) と \(b\) の 値で定まる関数 微分するのは \(L_{MSE} = N(w_{1}, w_{2}, w_{3}, b)\)・\(L_{MSE}\)を最小化するために 勾配降下法を使うとニューラルネットワークの学習が可能 1ノード、3入力 の勾配降下法 ・アルゴリズム (\(w1, w2, w3, b\))をランダムな値に設定 与えられた全訓練データに対して 損失関数\(L_{MSE}\)の勾配 を計算 勾配をもとに(\(w1, w2, w3, b\))の値をすこしだけ変化 損失が十分に少なくなるまで、勾配の計算 と すこしだけ変化 を繰り返す。・損失関数\(L_{MSE}\)の勾配は、与えられた全訓練データに対する平均となっている。 ・勾配 \(∇L_{MSE}\) は 関数\(L_{MSE}\) を \(w1, w2, w3 , b\) それぞれに対し 偏微分 したもの \(∇L_{MSE} = (\frac{∂L_{MSE}}{∂w_{1}}, \frac{∂L_{MSE}}{∂w_{2}}, \frac{∂L_{MSE}}{∂w_{3}}, \frac{∂L_{MSE}}{∂b})\)
(∇:ナブラ、参考)・シグモイド関数 \(σ(x)\) の微分は \(σ'(x)\) \(σ'(x) = e^{-x} / (1 + e^{-x})^2 \) \( = σ(x) * (1 - σ(x)) \) ( \(σ(x)\) を代入) \( = y * (1 - y) \) ( 出力 \(y\) の勾配(微分)は \( y * (1 - y)\))レイヤー (layer、層) ・ニューラルネットワークにおける機能の単位 ・複数の入力 と 出力 がある。 出力で得たい値の数と同じ個数だけノードが必要 このレイヤーの計算を行うノードは 2個・入力 と 出力間の接続は全接続(完全2部グラフ) 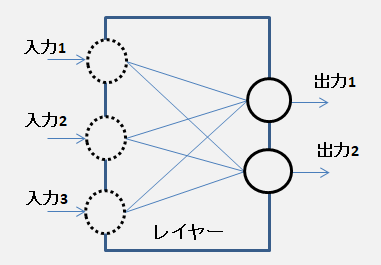 多層化 ・レイヤー1 への入力が ネットワークへの入力 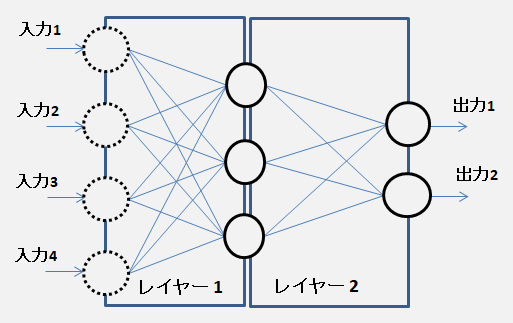 誤差逆伝播法 ・最後のレイヤーの前にレイヤーが存在する場合 最後のレイヤーは前のレイヤーに入力 x の調整を依頼できる。 入力 x の調整依頼は前のレイヤーへ伝播していける。 伝播はレイヤーをさかのぼり、最初のレイヤーに到達するまで続く。 TowLayerNet (lyersSample) 実装(sample)結合の仕方など ・全結合型 (fully-connected) MNIST学習の例・畳み込み型 (convolutional) ・再帰型 (recurrent) 3層構造 ・入力層 (input layer) ・中間層 (intermediate layer)、隠れ層 (hidden layer) ・出力層 (output layer) 分類問題 ノード数はクラス数(カテゴリ問題ならカテゴリ数) 回帰問題 ノード数は目標値の種類に合わせて決める。TowLayerNet (誤差逆伝播法mnistSample) ・入力値 - affine - relu - affine - softmax 入力値を「Affine1」に入れ、入力値と重みの総和を計算 「Affine1」の出力を「ReLU」に入れて活性化 「ReLU」の出力を「Affine2」に入れ、入力値と重みの総和を計算 「Affine2」の出力を「「Softmax-with-Loss」に入れ、活性化の結果/損失関数を求める。 「Softmax-with-Loss」から「Affine2」に逆伝播 (Affine2のパラメータを更新) 「Affine2」から「ReLU」に逆伝播 「ReLU」から「Affine1」に逆伝播 (Affine1のパラメータを更新)各層の計算 ・順伝播 (forward propagation) 前の層の出力値に「線形変換」と「非線形変換」を順番に施す。最適化 ・最適化の手法 (Optimizer) 計算グラフ ・計算の過程をグラフで視覚化して表す。 計算グラフを複数のノードとエッジで表現 |
| All Rights Reserved. Copyright (C) ITCL | |